지난 포스팅에 이어서 파이썬을 사용해 CSV 파일을 다루어 보겠습니다.
[Python/Python Study] - Python Basic - 파이썬 엑셀(Excel, CSV) 읽기 및 쓰기 (1)
CSV 파일 쓰기
CSV 파일을 읽기도 했으니 쓰기도 해야겠죠~?
import csv
data = [[1,2,3],[4,5,6],[7,8,9],[10,11,12],[13,14,15],[16,17,18]] # 이차원 리스트
with open('./resource/sample_test.csv','w', newline='') as f:
makewrite = csv.writer(f)
for value in data:
makewrite.writerow(value)
위의 코드를 작성 하고 실행 해 줍니다.
위의 코드를 천천히 읽어보면, data라는 이중 리스트를 resource 폴더 안에 sample_test.csv 의 형태로 'w' 한다 라는 얘기로 볼 수 있겠습니다~!
이전에 사용했던 reader() 말고, writer()를 사용 해 주고, 반복문 내에서 읽어 와 출력 해 주는 구문이 아닌 writerow() 로써 파일을 작성 해 주었습니다.
실행 후에 cmd 창에는 무엇도 남지 않지만 resource 폴더에 들어가서 sample_test.csv 파일을 확인 해 보면
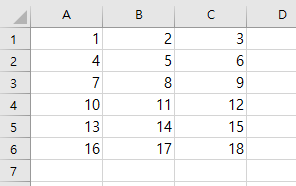
리스트가 csv 파일 내로 잘 들어가 있는 것을 확인 할 수가 있습니다 :)
위의 반복문의 형태는 조건을 검색하고 맞는 조건에 대해서 csv파일로 저장하기 좋은 형태로 작성 할 수 있습니다.
하지만 굳이 그럴 필요가 없는 경우에는 반복문을 사용하지 않고 한번에 저장 할 수 있습니다.
import csv
with open('./resource/sample4.csv','w',newline='') as f:
wt = csv.writer(f)
wt.writerows(data)writerow 는 한줄 한줄 작성하고, writerows 는 한번에 저장하는 것으로 생각하시면 되겠습니다!!
반복문을 타지 않고도 바로 데이터가 바로 저장 할 수 있습니다!
엑셀(EXCEL) 파일 읽기
이번에는 엑셀 파일을 읽어보도록 하겠습니다.
엑셀 파일은 확장자가 XSL, XLSX가 있는데요, 엑셀을 읽을 수 있는 오픈소스들이 많이 나와있습니다.

여러 오픈소스 모듈들이 있지만 가장 많이 사용 하는 것은 pandas를 주로 사용합니다.
pandas를 사용한다면 numpy도 같이 다운 되기 때문에 데이터 분석 등에도 유용합니다!
그럼 먼저, pandas를 사용을 위해 설치 과정을 함께하도록 하겠습니다~
Pandas 설치
pandas를 설치하도록 하겠습니다. 먼저, 이전에 설명드렸었던 가상환경을 사용 할 거에요.
아래의 접은글은, 가상환경을 사용하는 이유와 방법에 대해서 적어놓았던 글입니다
[Python/Python Study] - Python Basic - 가상환경 virtualenv(1)
Python Basic - 가상환경 virtualenv(1)
이전 포스트입니다 :) [Python/Python] - Python Basic - print 출력하기 Python Basic - print 출력하기 이전 포스팅입니다. 파이썬 설치와 에디터에 관한 내용입니다. [Python/Python] - Python Basic - 설치 Py..
woolbro.tistory.com
[Python/Python Study] - Python Basic - 가상환경 virtualenv(2) - 실행/설치/관리
Python Basic - 가상환경 virtualenv(2) - 실행/설치/관리
이전 포스팅입니다 :) [Python/Python] - Python Basic - 가상환경 virtualenv(1) Python Basic - 가상환경 virtualenv(1) 이전 포스트입니다 :) [Python/Python] - Python Basic - print 출력하기 Python Basic -..
woolbro.tistory.com
[Python/Python Study] - Python Basic - 가상환경 virtualenv(3) - 설치 패키지 사용하기
Python Basic - 가상환경 virtualenv(3) - 설치 패키지 사용하기
이전 포스팅입니다 [Python/Python] - Python Basic - 가상환경 virtualenv(2) - 실행/설치/관리 Python Basic - 가상환경 virtualenv(2) - 실행/설치/관리 이전 포스팅입니다 :) [Python/Python] - Python Basic..
woolbro.tistory.com
우선, 가상환경을 실행하도록 하겠습니다.
위의 가상환경 설정을 따라 하면 저와 같은 화면이 출력이 됩니다.
Window 파이썬 가상환경 실행은, Scripts 파일 내의 activate를 실행 시켜주면 됩니다.
Mac Os는 source bin/actiavte 혹은 bin 파일 에서 .activate 를 시켜주면 됩니다!

이제 가상환경 내부에 필요 모듈들을 설치하도록 하겠습니다
pip install xlrd
pip install openpyxl
pip install pandas
이렇게 설치 해 주시면 됩니다!
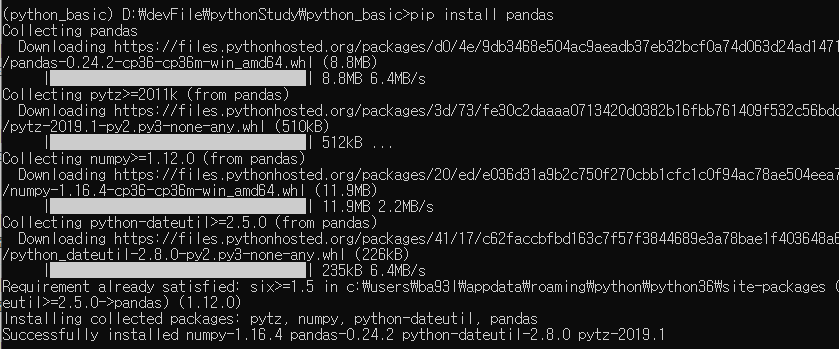
위 화면처럼 보여졌으면 설치가 완료 된 것입니다.
이번에는 sample.xlsx 파일을 열어보도록 하겠습니다.
위의 파일이구요, 열어보면 아래와 같이 나와있습니다.
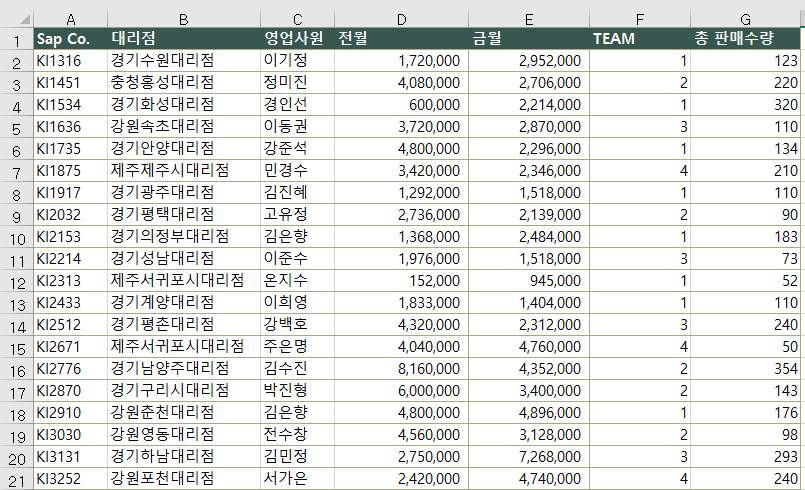
이제 pandas를 설치했으니 엑셀을 열어보도록 하겠습니다.
import pandas as pd
xlsx = pd.read_excel('./resource/sample.xlsx')위의 코드를 실행 시켰을때 오류가 나지 않으면, pandas 를 사용해 엑셀을 열기에 성공 한 것입니다 !!
간단하게 출력을 해 보겠습니다.
import pandas as pd
#sheetname = '시트명 or 숫자' , header = 숫자 skiprow=숫자
xlsx = pd.read_excel('./resource/sample.xlsx')
#상위 데이터 확인
print(xlsx.head())
print()
print(xlsx.tail())
print()
print(xlsx.shape) #행, 열
head()와 tail()은, 각각 위와 아래의 일부 데이터만 뽑아줍니다.
sheetname, header, skiprow 라는 옵션도 있습니다.
sheetname은 이름을 적어주거나 번호를 적어주면, 해당하는 시트의 이름 혹은 번호를 가져오게 되구요
header는 헤더로 설정할 숫자를 적어주고
skiprow 는 몇번 째 행을 생략 할 것인지를 적용 해 줍니다.
위의 옵션 모두 pd.read_excel에 써주면 됩니다.
xlsx = pd.read_excel('./resource/sample.xlsx',header=10)
Pandas로 엑셀, CSV 쓰기
import pandas as pd
xlsx = pd.read_excel('./resource/sample.xlsx')
xlsx.to_excel('./resource/pandas_result.xlsx',index=False) # index : 첫 열에 숫자 붙여주기
xlsx.to_csv('./resource/pandas_csv.csv',index=False)굉장히 쉽죠...? 읽은 xlsx 파일을 다시 다른 이름으로 작성 한 경우입니다.
각각 엑셀과 csv로 나뉘어 작성이 되었습니다.
'Old Branch' 카테고리의 다른 글
| Spring Project 스프링 프로젝트 시작하기 - Spring MVC 사용하기 (0) | 2019.07.10 |
|---|---|
| Spring Project 스프링 프로젝트 시작하기 - Spring MVC (7) | 2019.07.09 |
| Python Basic - 파이썬 엑셀(Excel, CSV) 읽기 및 쓰기 (1) (2) | 2019.07.05 |
| Python Basic - 파이썬 에러 및 예외 - 예외처리(2) (0) | 2019.07.04 |
| Python Basic - 파이썬 에러 및 예외 - 예외처리(1) (0) | 2019.07.03 |